

When we talk about Kubernetes, most of us think of agility, automation, and scale. But the moment you run stateful apps like databases or message queues, things become more complex. Persistent storage enters the picture, and with it come performance challenges and unexpected cloud costs.
If you've ever wondered "Why am I paying so much for storage?" or "Why does my app slow down under load even though I’ve provisioned enough?" the answer often lies in how storage is configured and managed.
Managing persistent volumes efficiently in Kubernetes isn't just about keeping things running. It's about running them smartly. The decisions you make around storage classes, volume provisioning, and cleanup can significantly impact both performance and cost.
This guide explores practical and effective strategies to help you maximize performance, minimize waste, and reduce storage costs in your Kubernetes environment.
1. Choose the Right Storage Class and Tune for Workload Needs
Each cloud provider offers multiple storage classes optimized for different performance and cost requirements. Choosing the right one ensures you're not overpaying for performance you don't need. For instance, AWS gp3 offers customizable IOPS and throughput at a lower cost, ideal for general workloads, while io2 is better suited for I/O-intensive applications like databases.
Kubernetes also supports allowVolumeExpansion, enabling you to start small and scale your storage when needed. This avoids provisioning excess capacity upfront.
Below is a YAML example for defining a cost-effective storage class:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3
allowVolumeExpansion: true
Here’s a quick comparison of storage classes across cloud providers:
Note: File storage options like EFS, Azure Files, and Filestore are included because they allow shared access across pods, unlike block volumes that are node-attached. Use them when multiple pods need to access the same data.
2. Enable Dynamic Provisioning and Right-Size Volumes
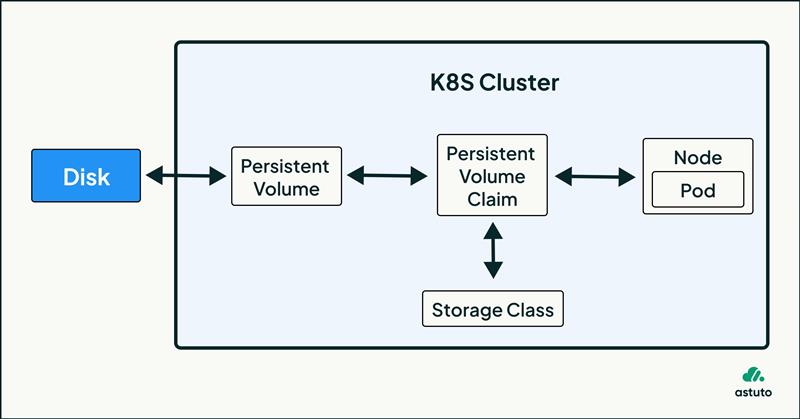
Dynamic provisioning in Kubernetes automates the creation of PersistentVolumes (PVs) when a PersistentVolumeClaim (PVC) is requested, removing the need for pre-provisioning storage. This not only reduces operational overhead but also ensures that storage is created only when needed. It helps avoid paying for idle, unused pre-provisioned volumes. For instance, consider the following configuration.
You can apply this YAML manifest to dynamically create a 10Gi storage volume using the fast-ssd StorageClass:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: fast-ssd
To right-size volumes, monitor usage using Prometheus metrics such as kubelet_volume_stats_used_bytes. When usage increases, you can expand the volume without downtime:
kubelet_volume_stats_used_bytes
When usage increases, you can expand the volume without downtime. Use the following command to resize an existing PersistentVolumeClaim (PVC):
kubectl patch pvc my-pvc -p '{"spec":{"resources":{"requests":{"storage":"20Gi"}}}}'
Using tunable storage classes like AWS gp3 also lets you adjust IOPS and throughput separately, helping you avoid upgrading to larger, more expensive volumes purely for performance.
3. Use Volume Snapshots for Backups
Kubernetes VolumeSnapshots, enabled via the Container Storage Interface (CSI), allow you to take point-in-time backups of PersistentVolumeClaims (PVCs). These snapshots are invaluable for disaster recovery, cloning environments, or creating rollback points before major application updates.
However, snapshots are stored as separate resources and accumulate storage costs over time, especially when not monitored. Old or unused snapshots can silently inflate your cloud bill.By regularly auditing and deleting obsolete snapshots, you can prevent unnecessary storage charges while retaining critical backups for business continuity.
Check the configuration given below to create a VolumeSnapshot in Kubernetes:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: db-snapshot
spec:
volumeSnapshotClassName: csi-aws-vsc
source:
persistentVolumeClaimName: db-data-pvc
This YAML creates a snapshot named db-snapshot from the existing PVC db-data-pvc using the AWS CSI snapshot class.
4. Clean Up Unused Persistent Volumes
After pods are deleted, associated PVs may remain in a Released or Failed state. These orphaned volumes are still billed by cloud providers unless manually cleaned up.
Automating the identification and deletion of unattached or stale volumes ensures you aren’t charged for resources that are no longer in use. Regular audits further prevent accumulation of abandoned storage.
Use this command to find orphaned volumes:
kubectl get pv --field-selector status.phase=Released
kubectl get pv --field-selector status.phase=Failed
To delete a specific orphaned volume:
kubectl delete pv <pv-name>
5. Use StatefulSets for Stateful Workloads
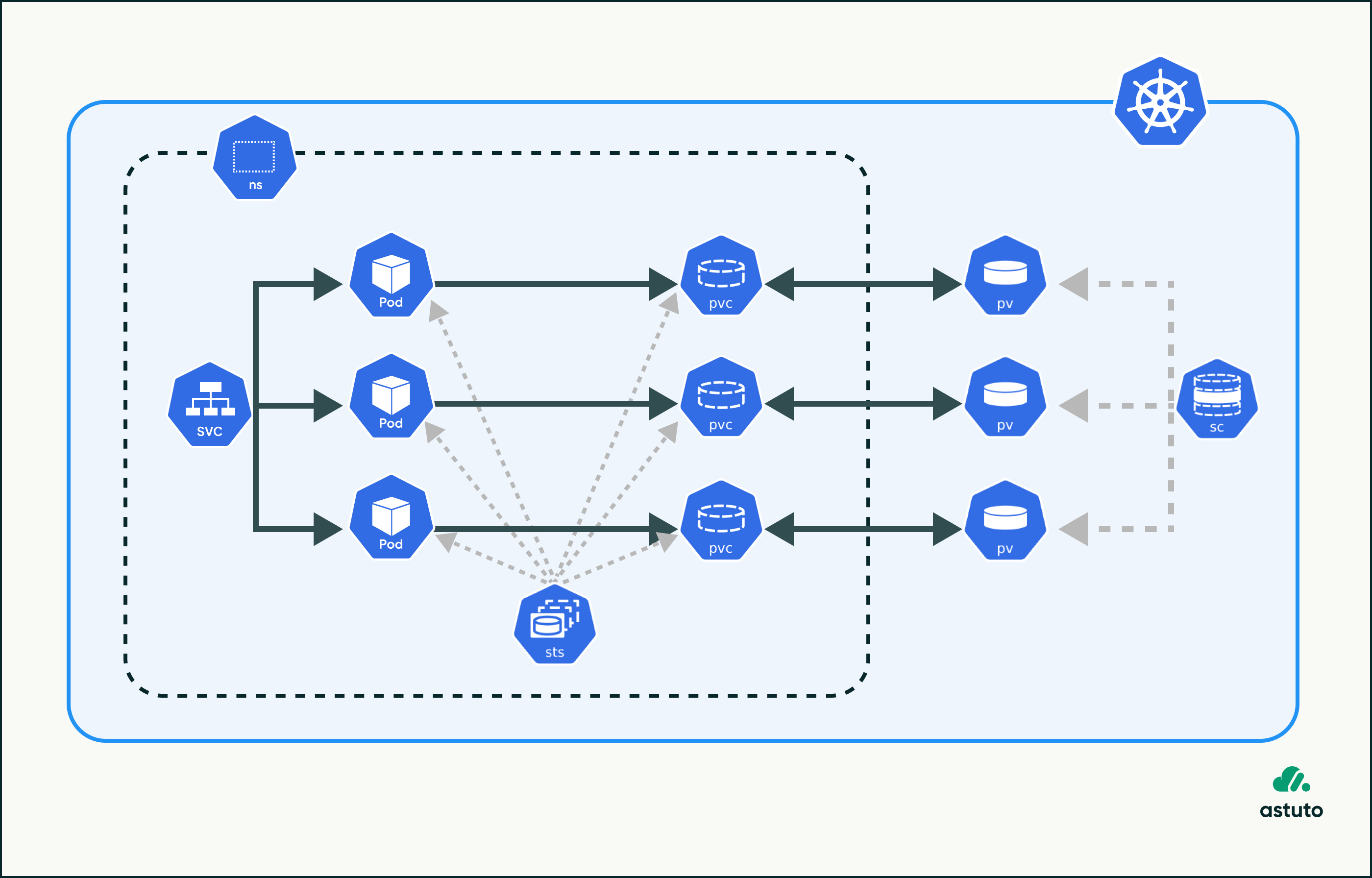
StatefulSets are ideal for applications like databases and queues that require persistent, stable identities and dedicated volumes per pod. Kubernetes ensures each replica gets its own volume via volumeClaimTemplates, enabling elastic scaling with no manual provisioning.
This means volumes are only created as needed, avoiding overprovisioning and reducing storage waste. For example, scaling a StatefulSet from 2 to 4 replicas will automatically provision 2 more PersistentVolumes based on the template.
6. Use Local Persistent Volumes for High Performance
Local Persistent Volumes (Local PVs) allow direct access to a node’s disk, offering extremely low-latency I/O. These are ideal for high-performance workloads like CI pipelines, caching, or log processing.
While Local PVs are tied to specific nodes, they persist beyond the lifecycle of a pod, unlike Kubernetes’ ephemeral storage (like emptyDir), which is removed when the pod is deleted.
Use Local PVs when you need:
- High IOPS performance
- Cost savings compared to cloud volumes (no per-GB charge)
- Node-level data persistence
YAML Example for a Local Persistent Volume:
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv
spec:
capacity:
storage: 100Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node-1
This binds the PV to a specific node (node-1) and uses a local path (/mnt/disks/ssd1).
Note: Local PVs should not be confused with pod-scoped ephemeral storage. They persist as long as the node exists and are useful for workloads that can tolerate node affinity.
References
1. Kubernetes Persistent Volumes Documentation
3. Kubernetes Dynamic Volume Provisioning
4. Kubernetes CSI Volume Snapshots
6. Azure Disk Storage Overview
8. Kubernetes Local Persistent Volumes
Conclusion
Persistent storage in Kubernetes is essential for maintaining the reliability and performance of stateful applications. Without a clear optimization strategy, it can lead to unnecessary costs and operational complexity.
By applying the practices covered in this blog, such as selecting the right storage classes, using dynamic provisioning, monitoring and resizing volumes, cleaning up unused resources, and leveraging local storage when suitable, you can build a storage setup that delivers strong performance and cost efficiency.




.jpeg)
